Introduction
UltraCart’s Data Warehouse (BigQuery) feature allows for a business to quickly setup a data warehouse of their customers, items, orders and auto order information with Google’s BigQuery database service. UltraCart will handle the data transfer into BigQuery on an automated base. Businesses can then use the information to feed support systems, write reports, and join up with other data systems for operational analysis.
Additional Benefits:
easy reporting in Google Data Studio / Microsoft Power BI
connect data to Microsoft Excel or Google Sheets
extract querying using the BigQuery CLI or SDK to extract the data set
Google Cloud Configuration
During the first part of this configuration tutorial we will establish a project within Google’s cloud, setup BigQuery, setup a Storage bucket, and setup a service account user with proper permissions.
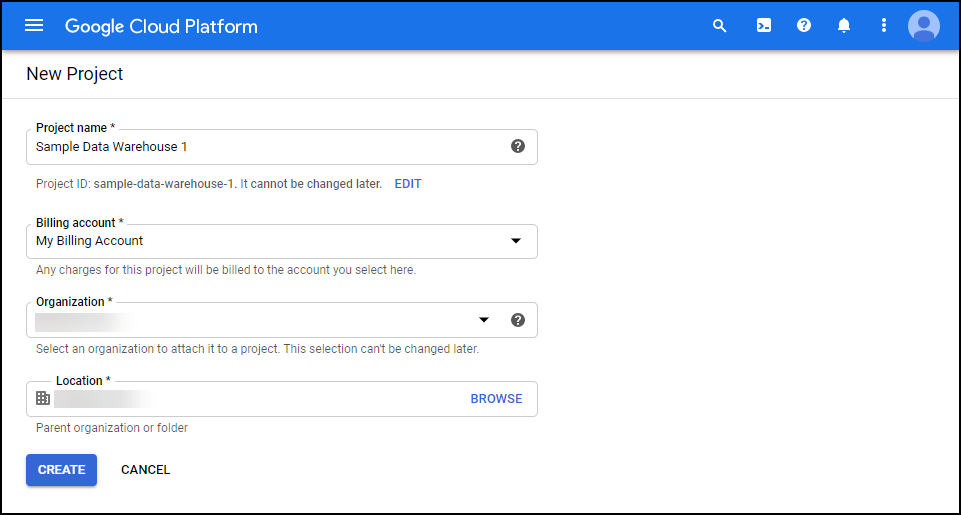
Setting up a Project
First create a new project within your Google Cloud account. Make sure you associate this project with a billing account otherwise your BigQuery tables will expire after 60 days because of Sandbox mode.
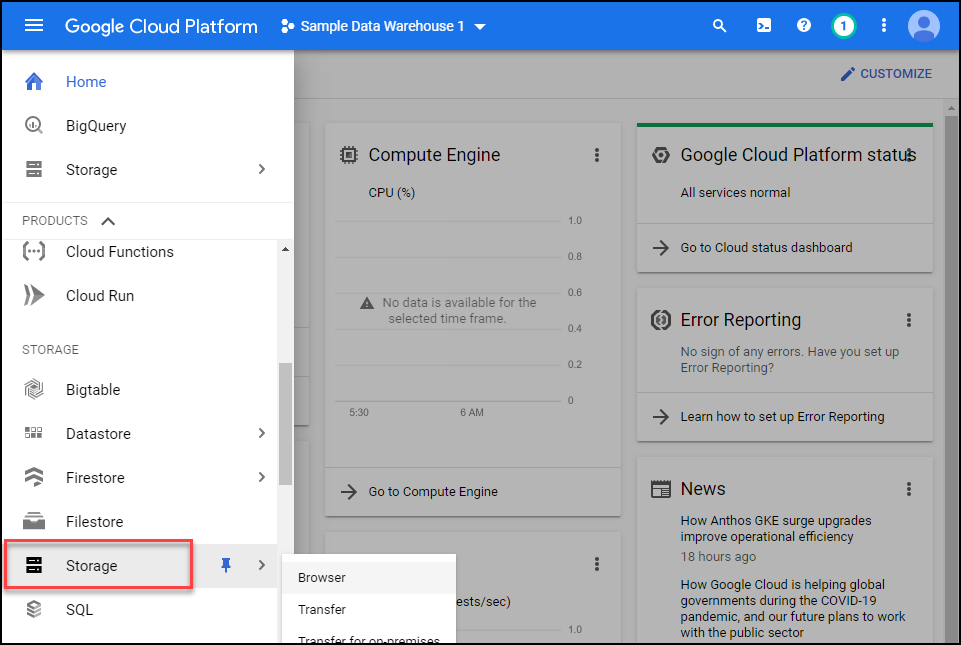
Setting up Storage Bucket
Next click on the menu, scroll down to Storage section and then click on storage.
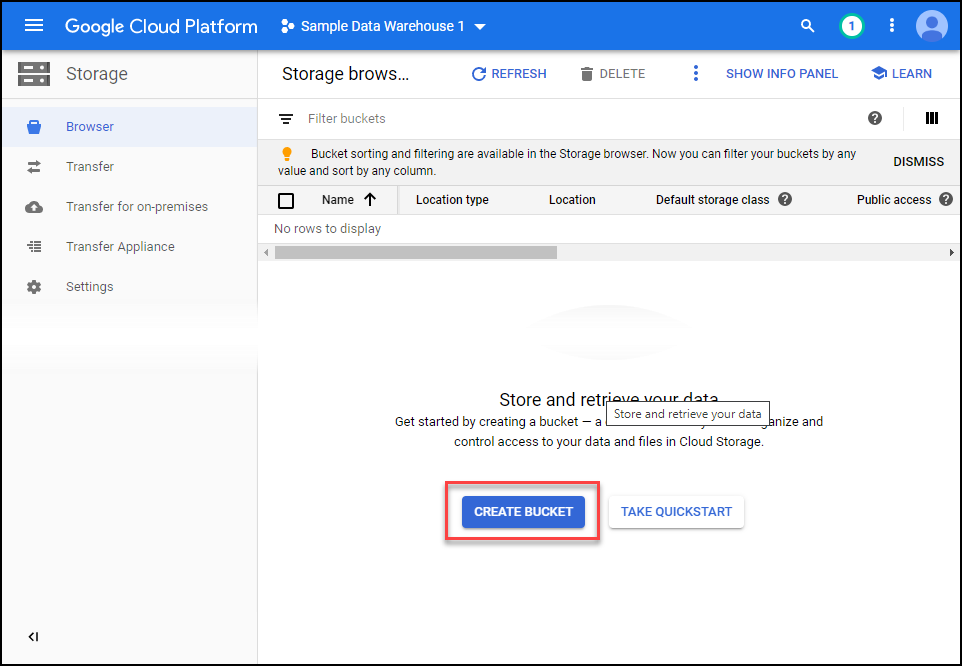
Click on the create bucket button as shown.
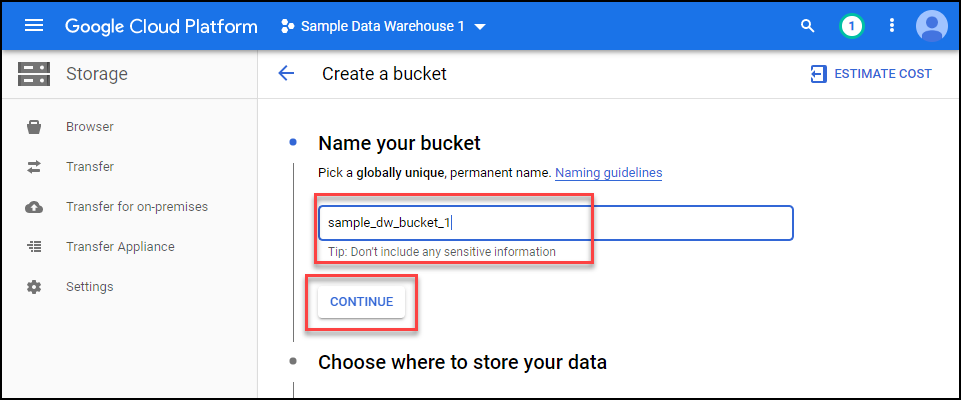
Give the bucket a name and click continue.
Select multi-region and the n click continue.
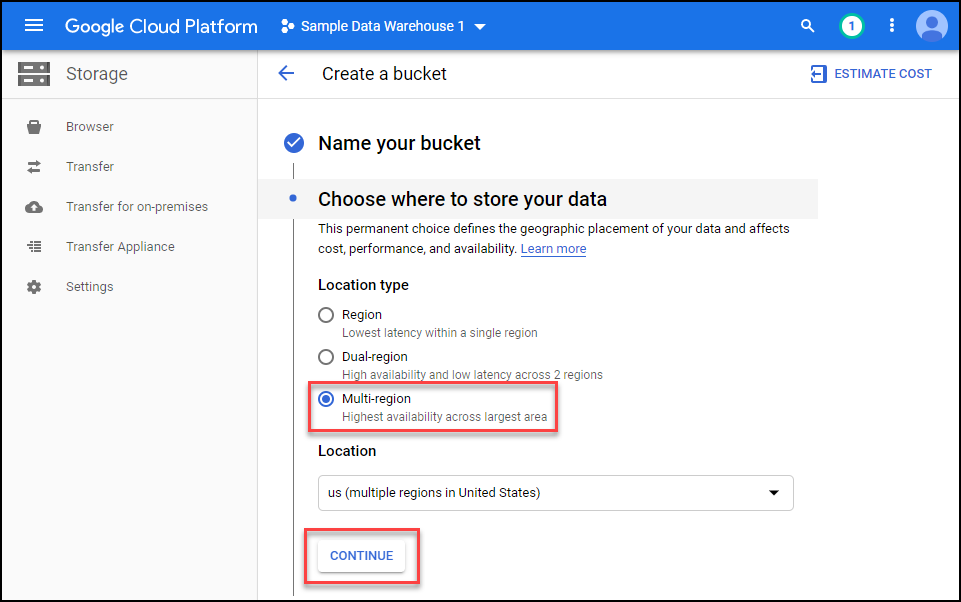
Select standard storage and then click continue.
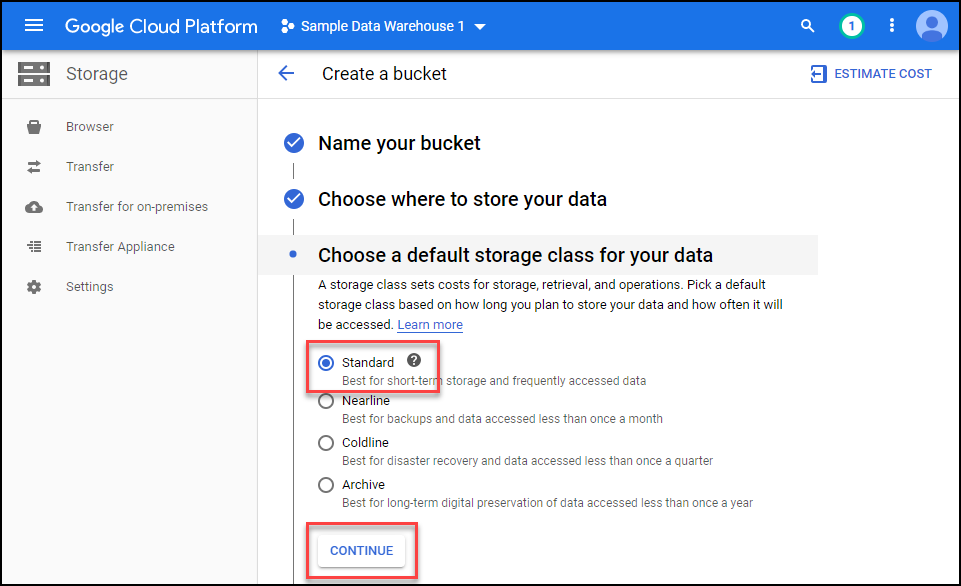
Select uniform access control and continue.
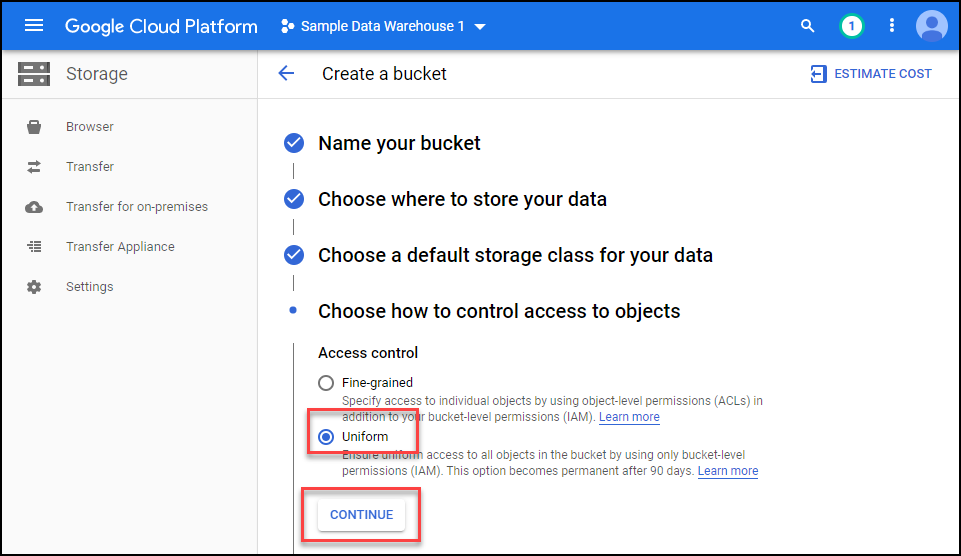
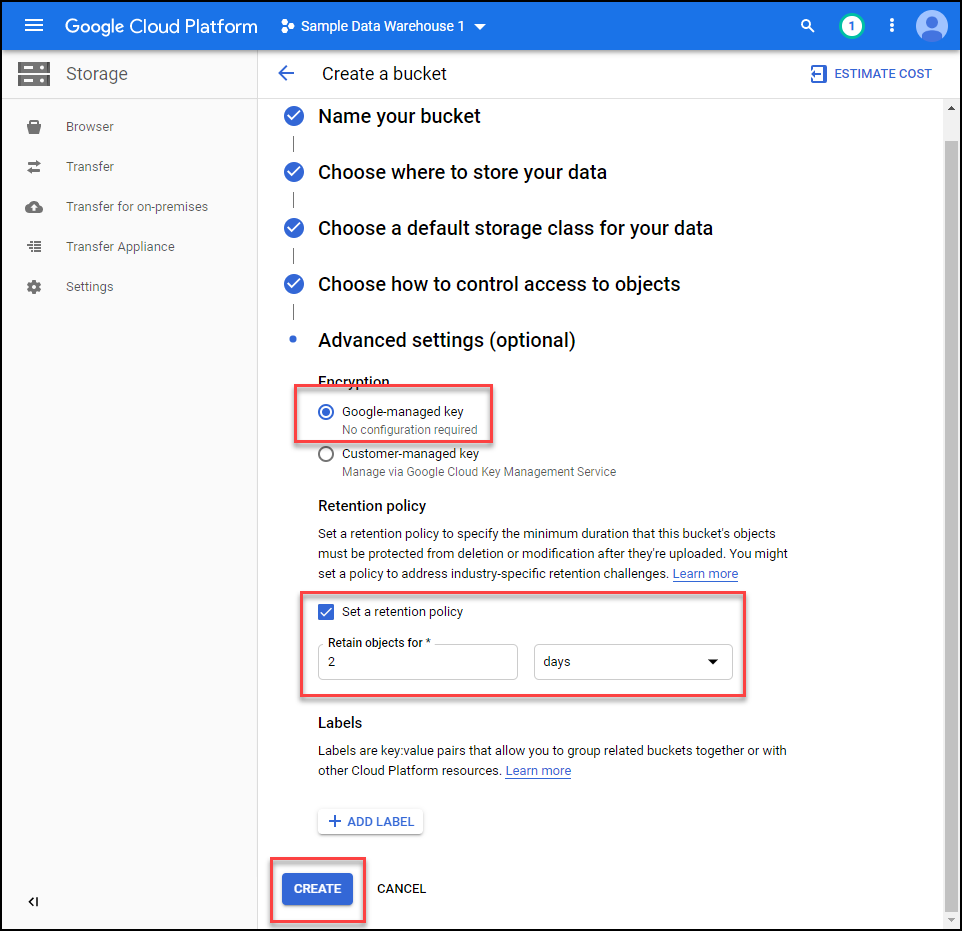
Select Google managed key, set an expiration of 2 days, and then click create.
Setup BigQuery
First click on BigQuery. In the screenshot below BigQuery has been pinned to the top of the list. You may need to scroll down to find it.
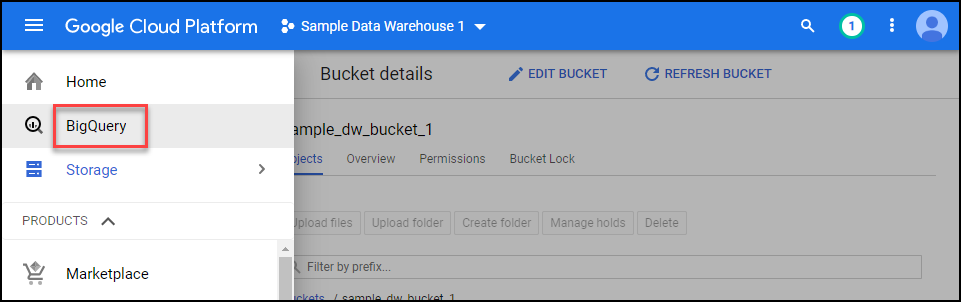
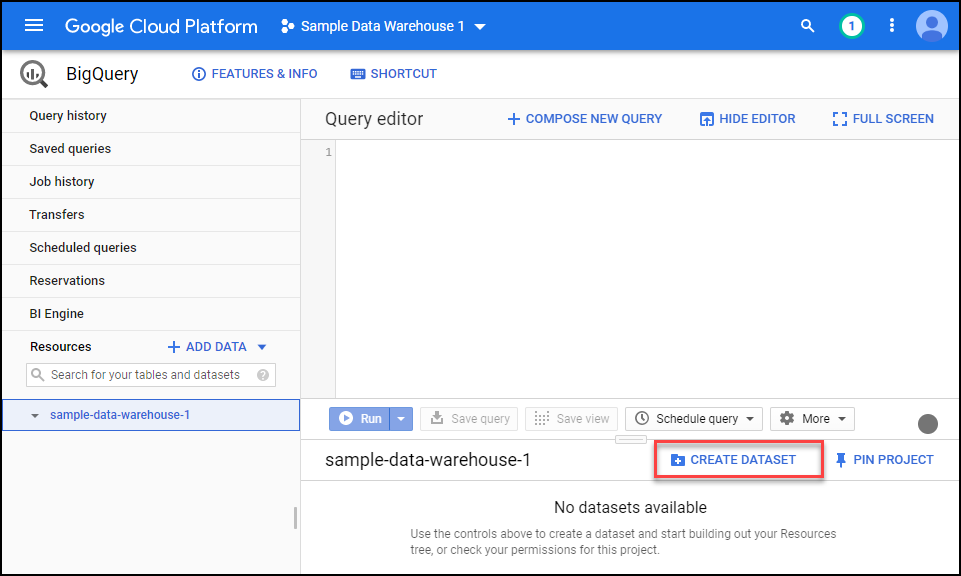
Click on the Create DataSet button. This is like creating a server within BigQuery to hold all the tables within your overall database.
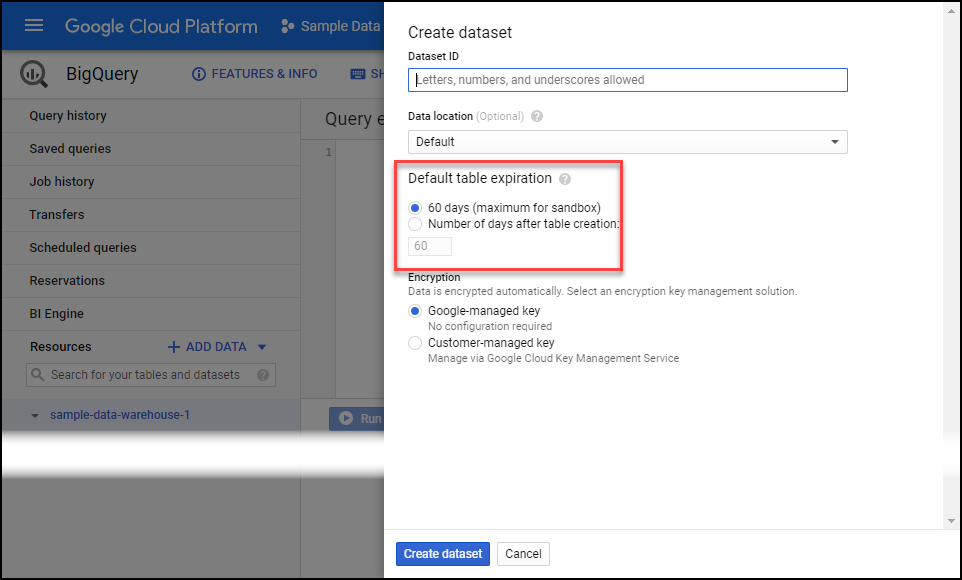
If your screenshot looks like the one below, stop and go assign a billing account to the Google project so that you exist sandbox mode.
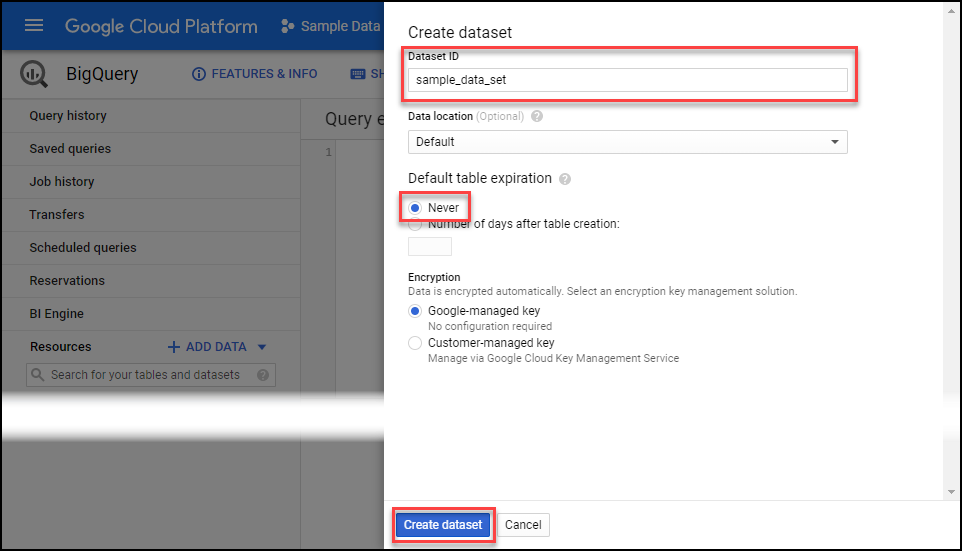
Configure the data set ID, configure it to never expire, and then click create dataset.
Setup IAM Role
Next we’re going to navigate to IAM & Admin then click roles.
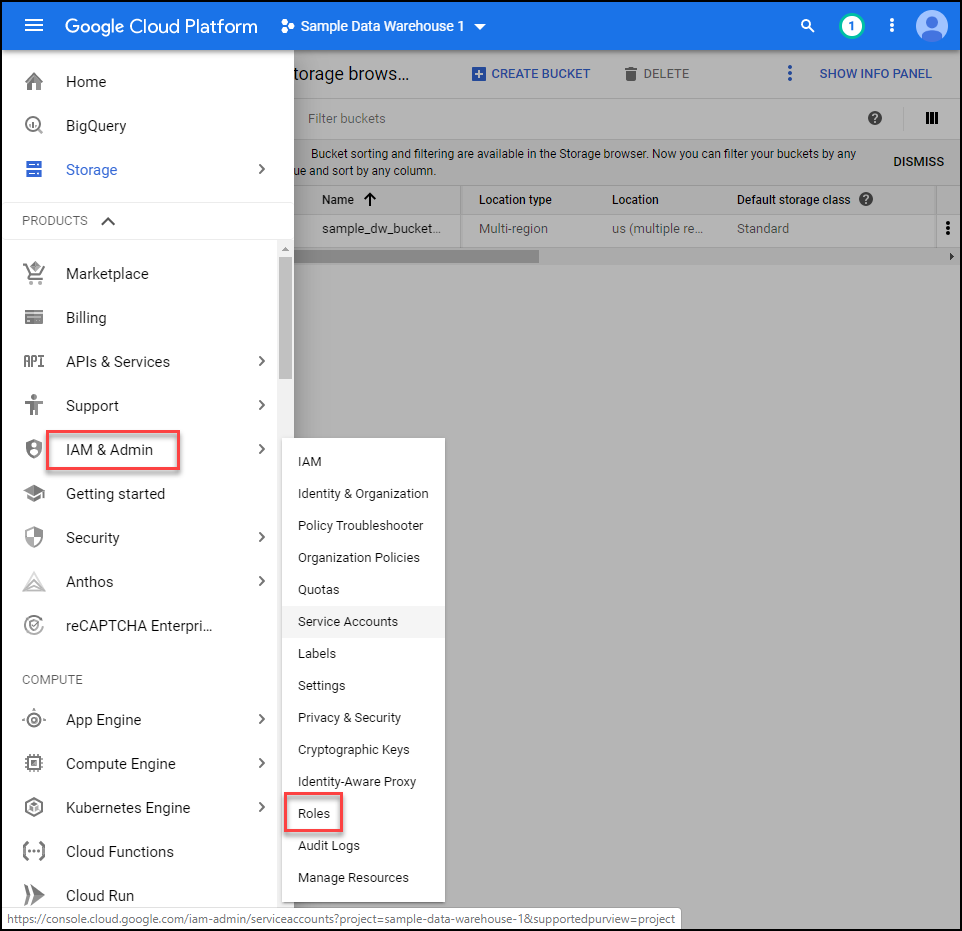
Create a new role as shown below. Make sure that your role has the following 16 permissions.
bigquery.datasets.create
bigquery.datasets.get
bigquery.jobs.create
bigquery.tables.create
bigquery.tables.delete
bigquery.tables.get
bigquery.tables.list
bigquery.tables.update
bigquery.tables.updateData
storage.buckets.list
storage.objects.create
storage.objects.delete
storage.objects.get
storage.objects.list
storage.objects.setIamPolicy
storage.objects.update
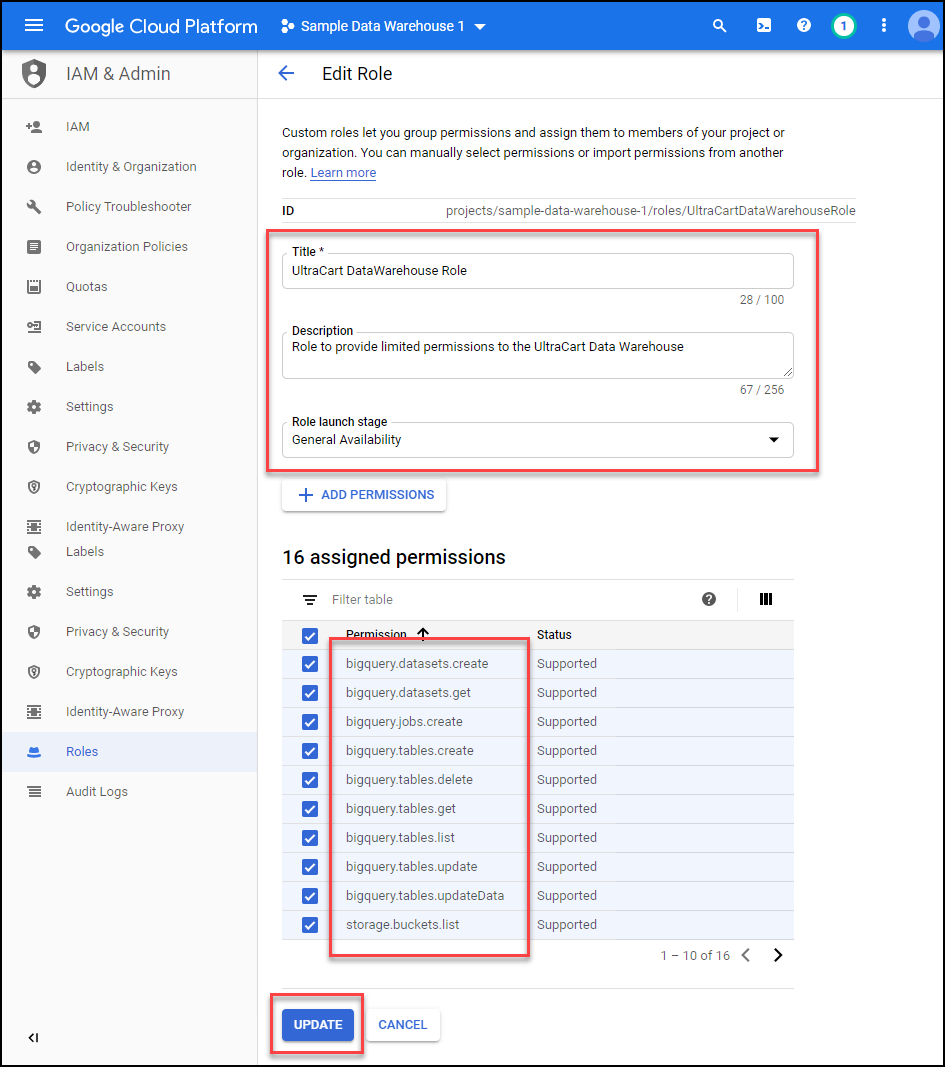
Make sure you added all 16 of the permissions shown in the list above. The screenshot only shows 10 of them.
Create IAM Service Account
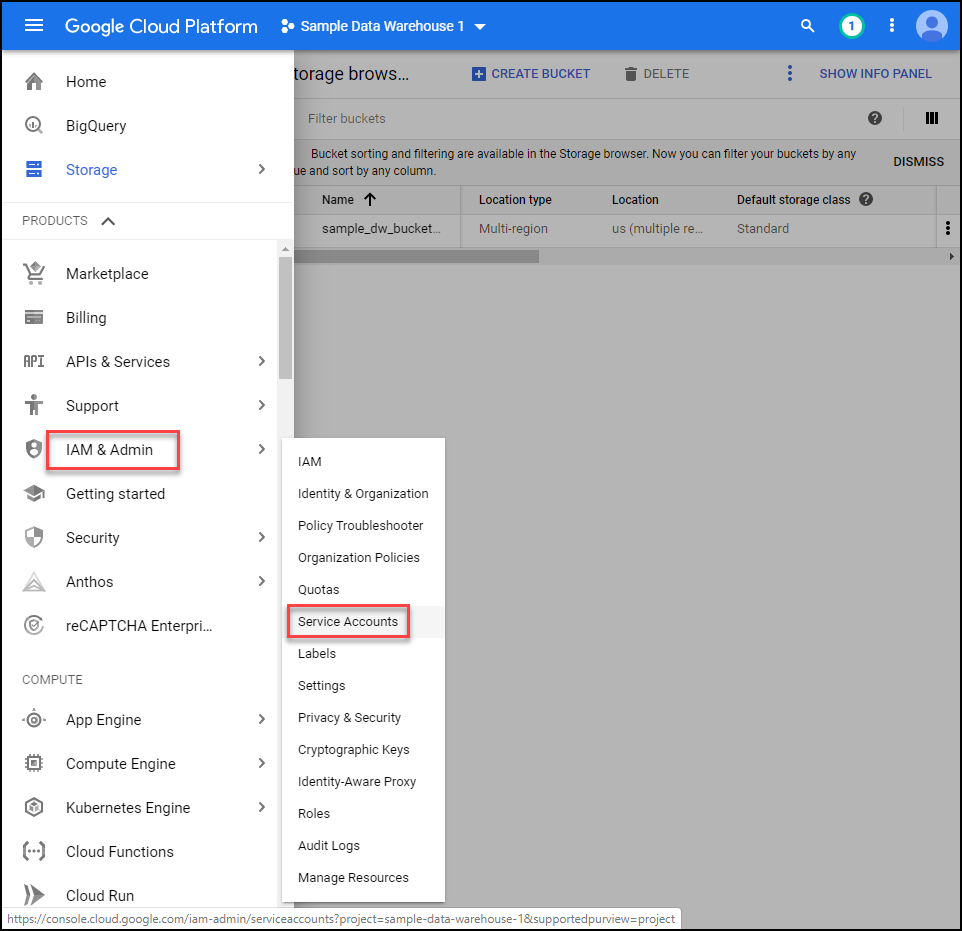
Now that we have a role created, let’s move on to the service account. Click IAM & Admin → Service Accounts as shown below.
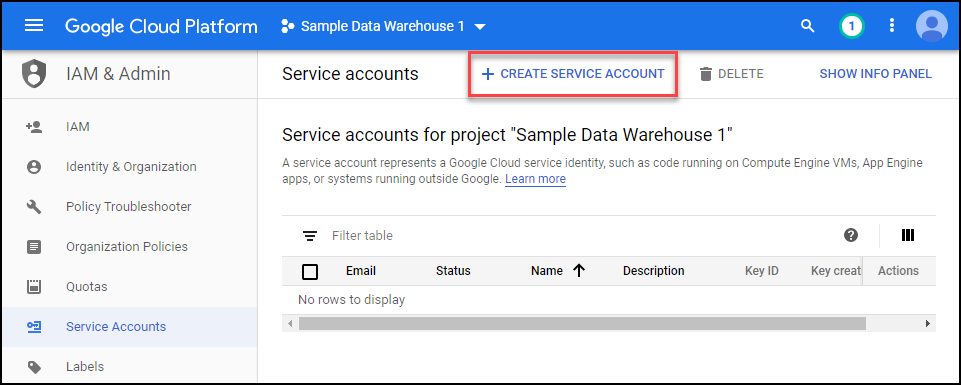
Click on create service account.
Give the service account a name and description then click create.
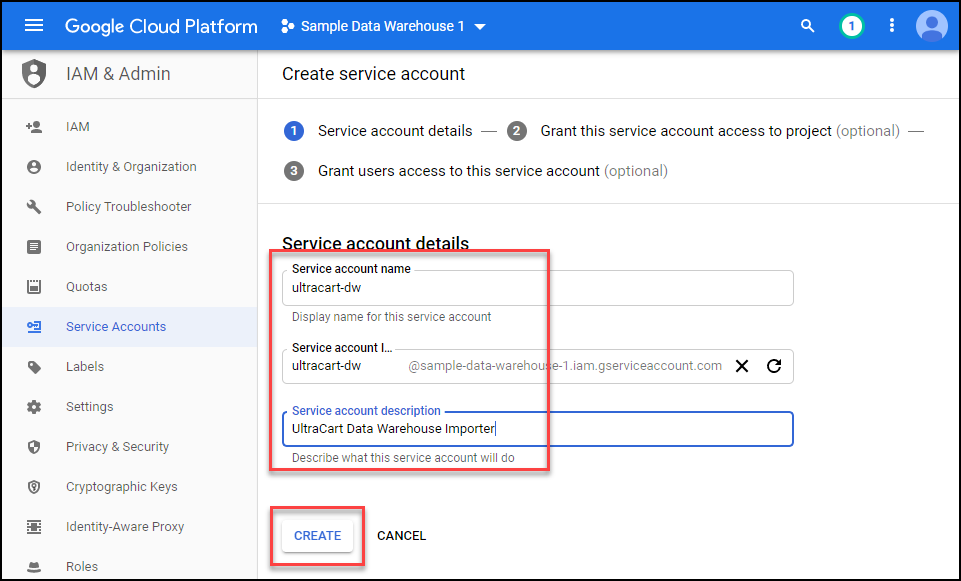
Next select the role that we just created so it is assigned to the service account.
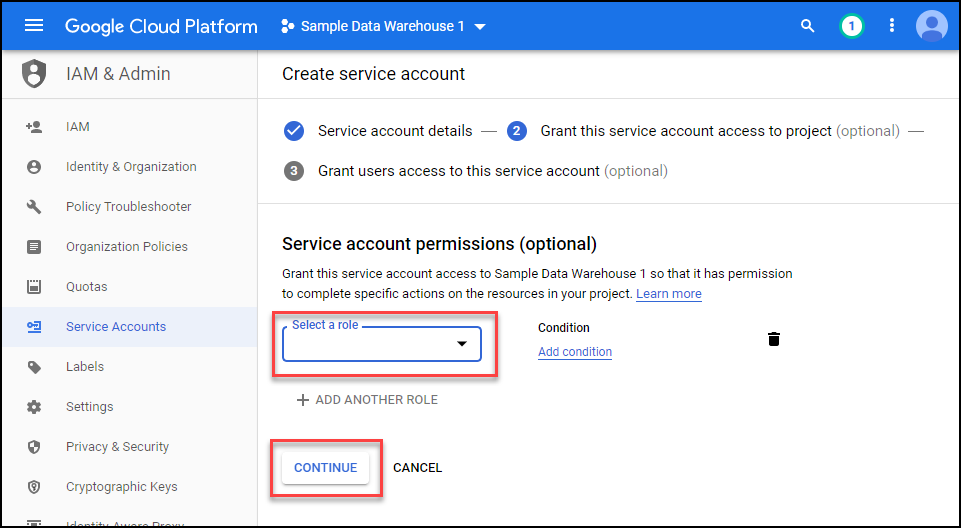
Next click on the create key button.
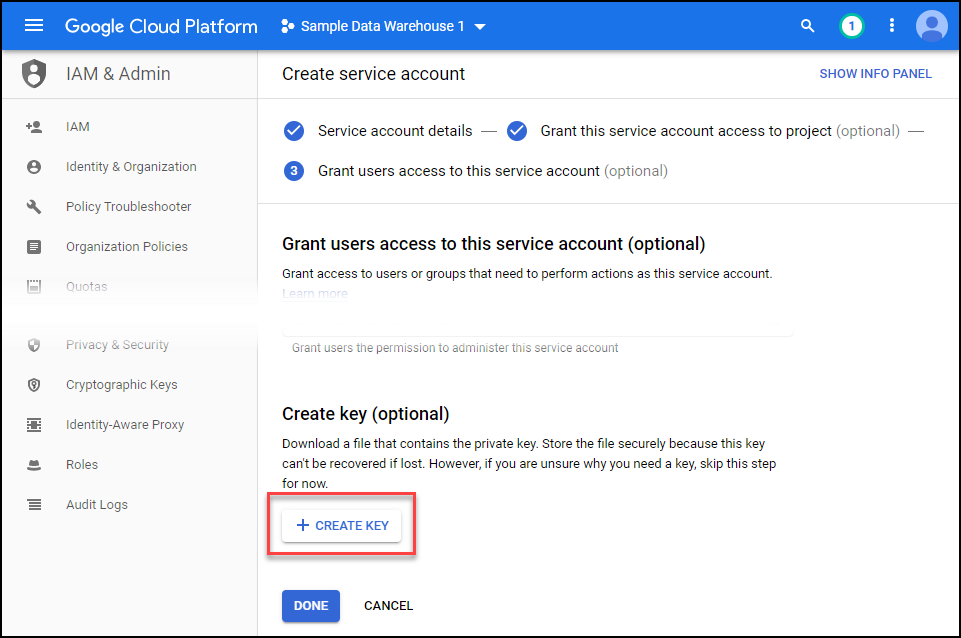
Keep the default selection of JSON and then click create. A file will download to your computer. Safe that as it will be the credentials file you upload into UltraCart.
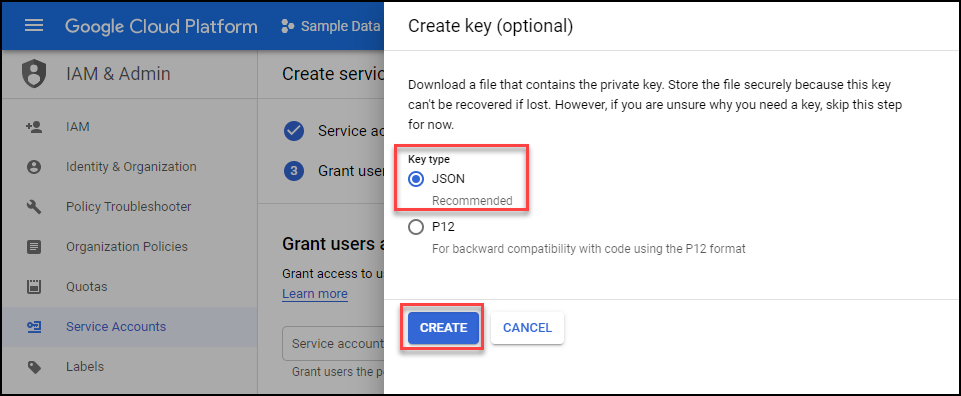
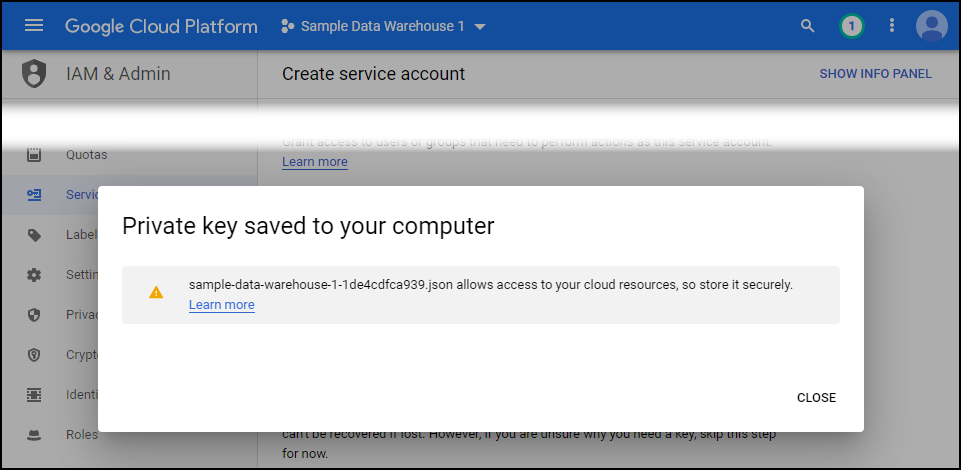
Add Service Account to Project.
Under IAM & Admin → IAM click on the Add button as shown below.
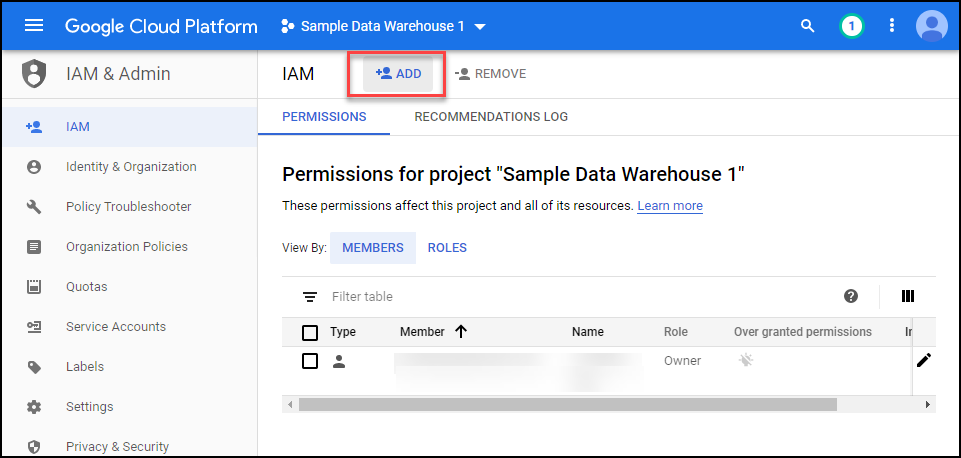
Search for your user, make sure to select the role and click save.
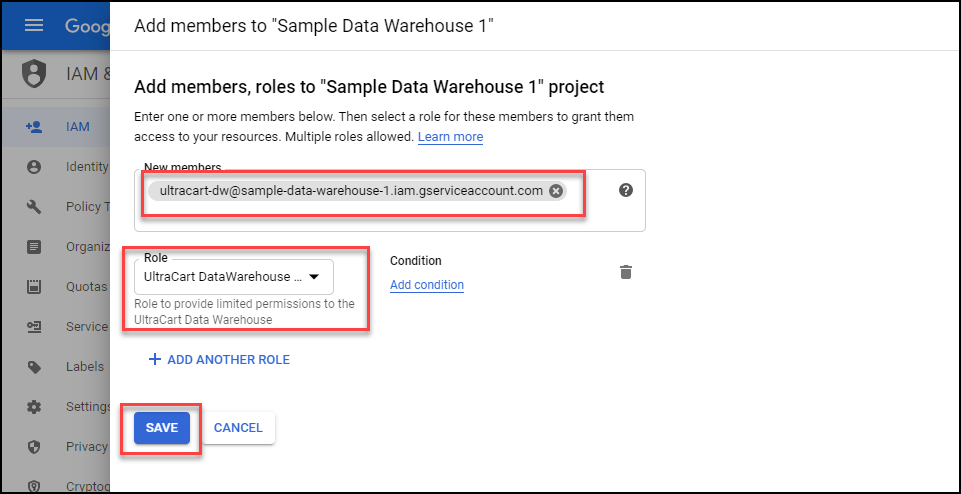
At this point there are three pieces of information that you should have:
JSON credentials file.
BigQuery DataSet Name.
Cloud Storage Bucket Name.
UltraCart Configuration
ATTENTION:
The OWNER USER is the only user that can configure the BigQuery integration.
Once its configured by the OWNER USER, they can grant access to the BigQuery side to additional users.
Navigate to Configuration → Developer → Data Warehouse (BigQuery)
Select the JSON key file, enter your BigQuery data set name, Cloud Storage bucket name, click activate, and name your tables as shown below. Once done click save.
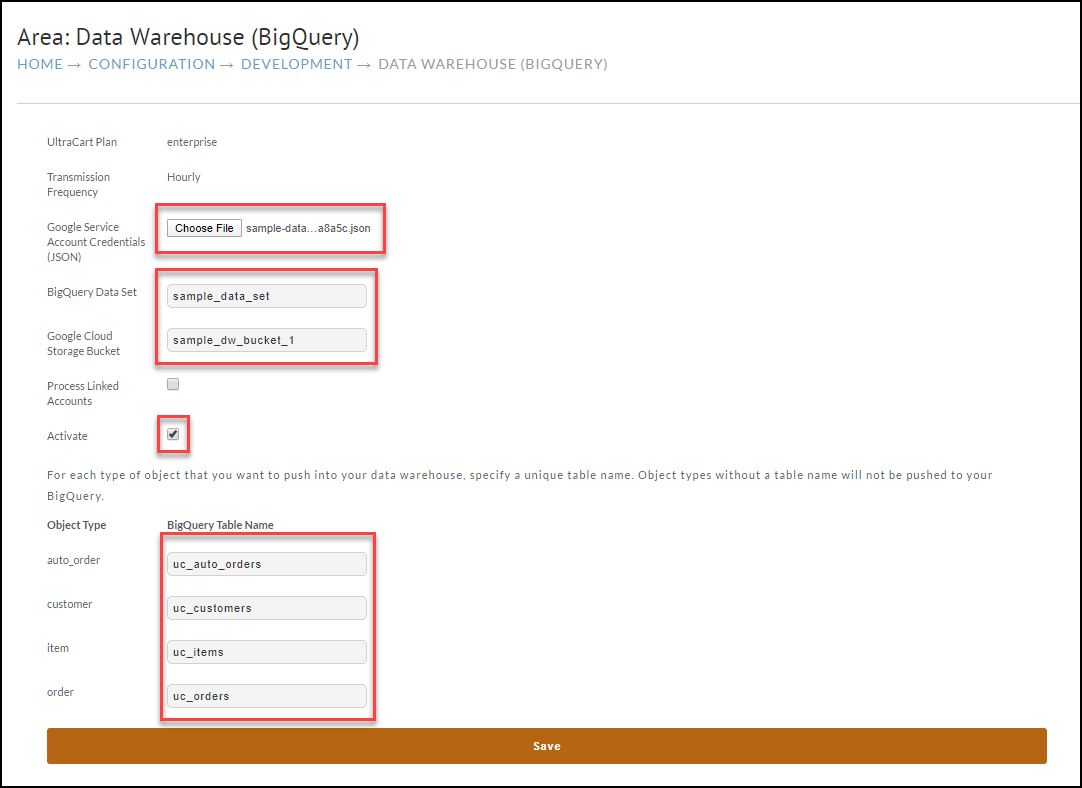
If everything saved without error, the data warehouse should populate within one hour the first time.
Google BigQuery tutorials
To learn more about using Google BigQuery, please see the following:
FAQ
What is a data warehouse?
A data warehouse is an enterprise grade system that is used for reporting and data analysis and is a core component of business intelligence. Data warehouses are the central repositories where data from one or more different sources are brought together for analysis. Often times these data stores contain both current and historical copies of data.
What is a BigQuery?
BigQuery is an enterprise data warehouse that solves the problem of operating the data warehouse by enabling super-fast SQL queries using the processing power of Google's infrastructure. Simply move your data into BigQuery and let Google handle the hard work. You can control access to both the project and your data based on your business needs, such as giving others the ability to view or query your data.
How does this data warehouse work?
UltraCart tracks what changes are happening to your data and periodically pushes fresh copies of auto orders, customers, items and orders into different tables within BigQuery using secure communication with your Google cloud project.
What UltraCart plans support it?
At this time only large and enterprise plans can utilize the data warehouse functionality of UltraCart.
How often does data update?
Large Plan - Once a week on Sunday
Enterprise Plan - Hourly
What data sets are supported?
At this time the objects that are pushed into your data warehouse are:
auto orders
customers
items
orders
What is the data model?
Each record within the BigQuery table is a hierarchy object that is provided to BigQuery as JSON data. It is almost identical to the REST API object model with a few difference covered below.
How does the data model different from the REST API?
All of the date time values on the records stored in BigQuery are in UTC. This differs from the typical EST that UltraCart runs in. The other change is that String[] type values have to be further nested to accommodate the way BigQuery loads data in.
What tools can connect to BigQuery?
There are a large variety of tools that can talk to BigQuery including:
SDKs in almost every popular language
Google Sheets
Google Data Studio
Microsoft PowerBI
Tableau
Qlik
Looker
Almost every popular analysis tool out there will have a connection to BigQuery.
What query language does BigQuery support?
BigQuery works with SQL as it’s query language. Documentation on their syntax is located here.
How does this data format differ from a traditional SQL database?
Traditional SQL databases do not operate on nested data within each row of the database. BigQuery fully supports nested hierarchical data within the table schema. If you’re used to SQL, but new to BigQuery make sure to look at the UNNEST function.
What does this feature cost?
The data warehouse integration feature of UltraCart is included with the large and enterprise plans.
What use cases can a business solve with a data warehouse?
Build complex custom reports based upon your order data.
Aggregation of order data from linked accounts into a single database table.
Scheduled reports (using Google Data Studio)
Company dashboards (using Google Data Studio)
and more…
How much does BigQuery cost?
The full pricing for BigQuery is located here. BigQuery is basically:
$0.02/GB of storage with the first 10GB free.
$5.00/TB of data processed during queries.
There are no hourly fees for having a BigQuery data set which makes it incredibly economical for more businesses.
Are linked accounts supported?
Yes, the parent account must be either large or enterprise and then it can ingest data from all the linked accounts.
What other data sets can you put in BigQuery to join up?
Common data sets that people drive into their BigQuery databases are:
Google Adwords spend
Facebook spend
What happens as the data model evolves?
If we add new fields to the data model which would change the schema, UltraCart will automatically recreate your BigQuery table instead of just performing an update.
How fast is the data warehouse available?
Typically within about 15 minutes your data warehouse will be initially populated.
What about other data warehouse software other than BigQuery?
At this time the data warehouse functionality is limited to BigQuery. If in the future another popular cloud native data warehouse software comes along we will consider an integration with it.
Enhancing Tables with Views
One of the powerful mechanisms of BigQuery is the ability to create a view. A view is a query of an existing table that then acts like a new table for the purposes of querying data. This is a powerful concept and one that everyone should learn. Views are not copies of your data so they are as live and reactive to changes as the base table.
There are two scenarios that you want to use a view for:
Flatten down the complex data into a simpler form for the purposes of reporting on in tools like Google Data Studio of Power BI.
Adding additional calculations into the base table for further analysis.
Adding Calculations to Auto Orders
The following query shows how to add:
Count of the number of rebills
Life time value of the customer
Average order value of the customer
How long the customer was active before the auto order was canceled or disabled
You can run this query to see the results. Then save this query as a view named “uc_auto_orders_with_stats”.
SELECT
-- Count number of rebills
ARRAY_LENGTH(rebill_orders) as number_of_rebills,
-- Life time value by adding original order plus rebill values
COALESCE(original_order.summary.total.value, 0) - COALESCE(original_order.summary.total_refunded.value, 0) +
COALESCE((
select SUM(COALESCE(r.summary.total.value, 0) - COALESCE(r.summary.total_refunded.value, 0)) from UNNEST(rebill_orders) as r
), 0) as life_time_value,
-- Average order value by adding original order plus rebill values then dividing by total number of orders
ROUND(
COALESCE(original_order.summary.total.value, 0) - COALESCE(original_order.summary.total_refunded.value, 0) +
COALESCE((
select SUM(COALESCE(r.summary.total.value, 0) - COALESCE(r.summary.total_refunded.value, 0)) from UNNEST(rebill_orders) as r
), 0) / (1 + ARRAY_LENGTH(rebill_orders))
,2) as average_order_value,
-- How long did the auto order last? Value will be null if still active
DATE_DIFF(COALESCE(canceled_dts, disabled_dts), original_order.creation_dts, DAY) as duration_days,
-- Retain all the other columns on uc_auto_orders
*
FROM `my-data-warehouse.my_dataset.uc_auto_orders`
Adding EST time zone dates to orders
BigQuery is going to treat all dates as the UTC time zone by default. This can cause some challenges when performing certain types of reports. The following query can be used to create a view “uc_orders_est” which contains fields that are shifted into the EST time zone.
select DATETIME(TIMESTAMP(o.creation_dts), "America/New_York") as creation_datetime_est, DATETIME(TIMESTAMP(o.payment.payment_dts), "America/New_York") as payment_datetime_est, DATETIME(TIMESTAMP(o.shipping.shipping_date), "America/New_York") as shipping_datetime_est, DATETIME(TIMESTAMP(o.refund_dts), "America/New_York") as refund_datetime_est, DATE(TIMESTAMP(o.creation_dts), "America/New_York") as creation_date_est, DATE(TIMESTAMP(o.payment.payment_dts), "America/New_York") as payment_date_est, DATE(TIMESTAMP(o.shipping.shipping_date), "America/New_York") as shipping_date_est, DATE(TIMESTAMP(o.refund_dts), "America/New_York") as refund_date_est, o.* from `my-data-warehouse.my_dataset.uc_orders` as o
Sample Queries
Important Note: If you’re going to write SQL queries with the nested data that is in the BigQuery tables, you’ll want to learn CROSS JOIN UNNEST and other array operations documented in the BigQuery documentation.
Active Auto Order Next Rebill
SELECT auto_order_oid, auto_order_code, status, enabled, original_order.order_id as original_order_id, orders.current_stage as original_order_current_stage, original_order.billing.first_name, original_order.billing.last_name, original_order.billing.email, original_order.shipping.day_phone_e164, original_order.shipping.state_region, original_order.shipping.postal_code, original_order.shipping.country_code, item_offset, future_schedules.item_id as future_schedule_item_id, future_schedules.shipment_dts as future_schedule_shipment_dts, future_schedules.unit_cost as future_schedule_unit_cost, future_schedules.rebill_count as future_schedule_rebill_count, REGEXP_EXTRACT(failure_reason, '^[^\n]+') as failure_reason, FROM `my-data-warehouse.my_dataset.uc_auto_orders` as auto_orders JOIN `my-data-warehouse.my_dataset.uc_orders` as orders on orders.order_id = auto_orders.original_order_id, UNNEST(auto_orders.items) as items WITH OFFSET AS item_offset, UNNEST(items.future_schedules) as future_schedules WITH OFFSET AS future_schedule_offset WHERE enabled = true and future_schedule_offset = 0 and orders.payment.payment_dts is not null and orders.payment.payment_method <> 'Quote Request' and orders.current_stage <> 'Rejected' and (items.no_order_after_dts is null or items.no_order_after_dts >= current_date()) ORDER BY future_schedules.shipment_dts ASC
Revenue Per Item Over a Certain Time Period
SELECT i.merchant_item_id, sum(i.total_cost_with_discount.value) as revenue_for_item, sum(i.quantity) as units_sold FROM `my-data-warehouse.my_dataset.uc_orders` CROSS JOIN UNNEST(items) as i WHERE creation_dts between "2021-07-01" and "2021-08-01" and i.kit_component = false group by i.merchant_item_id order by i.merchant_item_id
In this query we’re interacting with the order table. We want to join the items (which are a nested array) as another table. We use the CROSS JOIN UNNEST operation to do this. Once we have the tables joined it’s a pretty standard group by and sum over type query.
Query Table Size in GB
select table_id, ROUND(sum(size_bytes) / (1024 * 1024), 2) as size_in_gb from `my-data-warehouse.my_dataset.__TABLES__` group by table_id
This query will show you the size of the tables you have in BigQuery.
Order ID Experiment Variations
SELECT order_id,
(
select params.value.text from UNNEST(events.params) as params where params.name = 'expid'
) as experiment_id,
(
select params.value.num from UNNEST(events.params) as params where params.name = 'expvid'
) as experiment_variation_number
FROM `my-data-warehouse.my_dataset.uc_storefront_recordings`
CROSS JOIN UNNEST(page_views) as page_views
CROSS JOIN UNNEST(page_views.events) as events
WHERE order_id is not null and events.name = 'experiment'
This query will show which experiment and variation each order went through (this requires screen recordings).